言简意赅 の Python3
Python 诞生于 20 世纪 90 年代初,是一款非常简洁易读的解释型脚本语言;擅长于科学计算与图形处理,传统的计算机视觉库 OpenCV、三维可视化库 VTK、医学图像处理库 ITK都提供了 Python 调用接口,Python 也原生提供了 NumPy、SciPy、matplotlib等强大的科学计算扩展库。Web 应用开发方面,Python 也提供有 Django、Tornado 等开发框架。概而言之,得益于强大的开源社区支持,Python 已经成为一门功能丰富的胶水语言。
![]()
本文示例代码基于Python
3.6.6版本编写,在简单介绍相关语法以及 pip、virtualenv
等扩展库的使用之后,将会实现一个基于官方 XML
解析库ElementTree的 SVG
图片合并小程序。文中涉及的代码已经提交至笔者的 Github,需要的朋友可以直接进行克隆,任何缪误或者建议请向我提交issue。如果需要采用
Python 进行 Web 开发,可以参见我的《使用 Django2
快速开发 Web 项目》一文。
Hello World
Python 运行环境安装非常方便,Windows 操作系统下直接前往Python 官网下载安装包(注意添加环境变量),使用 Debian 软件包格式的 Linux 操作系统可以通过如下命令安装:
1 | ➜ sudo apt install python3 |
笔者的 Linux
开发环境下,同时存在Python 3.6.6和Python 2.7.15两个版本,因此在
Z-Shell
命令行中运行Hello World程序时,需要显式输入python3,以指定操作系统打开Python 3.6.6运行环境。
1 | ➜ / python3 |
代码执行完毕后,可以通过按下
CTRL + D或者输入exit()退出 Python 运行环境。
当然,也可以单独将print("Hello World!")保存到一个独立的test.py代码文件,然后在命令行当中直接开始运行。
1 | ➜ 1-hello-world python3 test1.py |
默认情况下,Python
源代码是以UTF-8格式进行编码的,但可以通过向源文件头部添加如下声明来指定编码格式。
1 | # -*- coding: utf-8 -*- |
可以在.py脚本文件的头部手动添加 Python
解释器的路径,从而在 Linux
系统可以方便的通过./test1.py执行该脚本,避免python3 test1.py写法的繁琐。
1 | #!/usr/bin/python3 |
Python 使用缩进来表示代码块,相同代码块的语句必须包含相同的缩进空格数。
1 | # -*- coding: utf-8 -*- |
代码将只会执行最后的print语句,运行结果如下:
1 | ➜ 1-hello-world git:(master) ✗ python3 test2.py |
变量
Python
是弱类型语言,因此声明变量时不需要指定数据类型,现在修改上一步的例子,声明一个infomation变量然后输出:
1 | infomation = "Hello World!" |
执行结果如下:
1 | ➜ python3 test1.py |
相对 C、Go、Java 等强类型语言,Python 的语法结构更为松散,但是变量的命名依然需要遵循以下规则:
- 变量名只能包含字母、数字、下划线,但不能以数字开头,例如
infomation_1是合法的变量声明,但是1_infomation则属于非法。 - 变量名不能包含空格,不过可以使用下划线来分隔单词,例如
print_something是合法的,但是print something属于非法。 - 不能使用 Python
关键字、函数名称作为变量名,例如
lambda、yield、raise、def、nonlocal、elif、assert、except、pass、with。 - 建议使用小写字母作为变量名,并且谨慎使用小写字母
l和大写字母O,因为两者很容易被代码阅读者混淆为数字1和0。 - 变量命名尽量见文知意,避免过度的缩写,例如
person_name明显比person_n更加易读。
熟悉了变量命名规则之后,进一步扩展上面的程序,对变量infomation重新进行赋值然后打印输出:
1 | infomation = "Hello World!" |
执行后将会输出两次打印结果:
1 | ➜ python3 test2.py |
traceback(回溯,追踪)是 Python 语法解析器提供给开发人员的代码错误提示信息,可以更加直观的定位错误发生的代码位置。
1 | ➜ python test3.py |
注释
Python 使用#作为注释声明符号:
1 | # Comment |
或者使用多个井号来声明多行注释:
1 | # First Comment |
网络上有些文章介绍使用
3个单引号'''或双引号"""声明多行注释是不正确的做法,因为字符串内声明的内容虽然不会被直接显示给用户,但是 Python 语法解释器会耗费额外的计算资源解析这些字符串,而使用#号声明的注释并不会在存在这样的问题。
数据类型
Python
是弱类型语言,使用前不需要专门声明,赋值之后变量即被创建。Python
一共拥有 5
种标准的数据类型:数值(Number)、字符串(String)、列表(List)、元组(Tuple)、字典(Dictionary)。Python
这 5
种标准数据类型除了通过字面量方式声明之外,还可以通过构造函数int()、float()、complex()、str()、list()、tuple()、dict()进行声明。
Python
当中除了这五种标准数据类型之外,还存在二进制序列类型(bytes,
bytearray,
memoryview)、集合类型(set,
frozenset)等衍生的数据类型,本文这里并不将其作为基本数据类型进行介绍,开发人员可以结合官方文档的《Internal
Objects》章节按需进行查阅。
数值 Number
由于 Python 非常适合于科学计算用途,因此对于数值类型方面内容的讲解篇幅相对较大。Python 的数值类型分为整型(精度不限)、浮点类型(底层使用 C 语言的双精度浮点类型实现)、复数类型(包含实部和虚部)三种,其中布尔类型是作为整型的子类型出现。
当前硬件设备对 Python 浮点数精度的相关支持信息,可以通过如下代码进行查看。
1 | import sys |
上述代码在笔者的 64 位 Linux 系统上执行的结果如下:
1 | sys.float_info(max=1.7976931348623157e+308, max_exp=1024, max_10_exp=308, min=2.2250738585072014e-308, min_exp=-1021, min_10_exp=-307, dig=15, mant_dig=53, epsilon=2.220446049250313e-16, radix=2, rounds=1) |
全部数值类型都支持的运算符:
| 操作 | 结果 | 示例 |
|---|---|---|
x + y |
x与y的和 |
3 + 2,结果为5。 |
x - y |
x与y的差 |
5 - 1,结果为4。 |
x * y |
x与y的乘积 |
3 * 9,结果为27。 |
x ** y |
x的y幂次方 |
2 ** 3,结果为8。 |
x / y |
x和y的商 |
8 / 2,结果为4.0。 |
x // y |
x和y的商取整 |
4 // 3,结果为1。 |
x % y |
x与y的余数 |
12 % 7,结果为5。 |
-x |
取x的负数 |
-3。 |
+x |
取x的正数,原值不会变化 |
+3。 |
全部数值类型都支持的方法:
| 操作 | 结果 | 示例 |
|---|---|---|
abs(x) |
取x的绝对值 |
abs(-32.3),结果为32.3。 |
int(x) |
取x的整型 |
int(3.84),结果为3。 |
float(x) |
取x的浮点类型 |
float(5),结果为5.0。 |
complex(re, im) |
一个以re作为实部im(默认为0)作为虚部的实数 |
complex(2.02, 3.3),结果为(2.02+3.3j)。 |
c.conjugate() |
复数c的共轭复数 |
(complex(2.02, 3.3)).conjugate(),结果为(2.02-3.3j)。 |
divmod(x, y) |
由(x // y, x % y)组成的值对 |
divmod(12, 7),结果为(1, 5)。 |
pow(x, y) |
x的y幂次方,等效于x ** y |
pow(2, 3),结果为8。 |
整型的位操作:
| 操作 | 结果 | 示例 |
|---|---|---|
x & y |
按位与 | 3 & 2,结果为2。 |
x | y |
按位或 | 3 | 2,结果为3。 |
x ^ y |
按位异或 | 3 ^ 2,结果为1。 |
x << n |
左移位 | 3 << 2,结果为12。 |
x >> n |
右移位 | 3 >> 2,结果为0。 |
~x |
按位取反 | ~3,结果为-4。 |
Python 的 Boolean
值由False和True两个静态对象组成,其它对象参与布尔运算时,通常被认为是True(除非重写其类定义当中的__bool__()方法并返回False,或者重写__len__()并返回0),下列对象在布尔运算中会被认为是False。
- 被定义为
False的等效常量:None、False。 - 任意值为
0的数值类型:0、0.0、0j、Decimal(0)、Fraction(0, 1)。 - 空的序列或者集合:
''、()、[]、{}、set()、range(0)。
包含布尔结果的 Python 内建函数总是返回
0和False或者1和True。
特别需要注意的是:布尔运算or和and总是返回其中一个操作数本身,请参见下面的布尔运算符说明表:
| 操作 | 结果 | 示例 |
|---|---|---|
x or y |
如果x为假,那么返回y,否则返回x |
2 or 3,结果为3。 |
x and y |
如果x为假,那么返回x,
否则返回y |
2 and 3,结果为2。 |
not x |
如果x为假,
那么返回True, 否则返回False |
not 0,结果为True。 |
Python 拥有 6
个比较运算符,其各自的运算优先级相同,可以随意链式使用。例如:x < y <= z与x < y and y <= z等效。
| 操作符 | 结果 | 示例 |
|---|---|---|
x < y |
严格小于 | 3 < 1,结果为False。 |
x <= y |
小于或等于 | 4 <= 4,结果为True。 |
x > y |
严格大于 | 12 > 33,结果为False。 |
x >= y |
大于或等于 | 21 >= 19,结果为True。 |
x == y |
等于 | ["A", "B"] == ["A", "B"],结果为True。 |
x != y |
不等于 | 21 != 21,结果为False。 |
x is y |
对象引用地址的相等性判断 | ["A", "B"] is ["A", "B"]结果为False。 |
x is not y |
对象引用地址的相等性判断的结果取反 | ["A", "B"] is not ["A", "B"]结果为True。 |
字符串 String
Python 中的字符串是一个不可变的 Unicode
字符序列,可以保存在str对象或者字符串字面量当中。其中,字符串字面量可以通过如下
3 种方式书写:
单引号:'allows embedded "double" quotes'。双引号:"allows embedded 'single' quotes"。三引号:'''Three single quotes'''、"""Three double quotes"""。
三引号字符串可以书写到多行,并且所有的空格都将会完整的保存下来。
Python
字符串同样可以通过class str(object=b'', encoding='utf-8', errors='strict')构造器进行创建。
1 | str("hello python!") == "hello python!" # True |
Python 字符串可以进行索引,字符串第 1
个字符的索引为0,子字符串可以使用分割符:来指定。
1 | hank = "uinika" |
列表 List
列表 List 是一个可变的序列(即可以对列表的每个数据项进行修改),用于存储同类数据的集合,可以通过如下方式进行创建:
- 使用方括号
[]表达一个空的列表,例如[]; - 使用方括号
[]并且使用逗号,分隔每项数据,例如:[1, 2, 3]; - 使用列表理解,例如
[x for x in iterable]; - 使用
list()或者list(iterable)构造器;
1 | # 定义列表 |
可以使用class range(stop)或者class range(start, stop[, step])生成一系列数值,通常指定for循环的次数。
1 | for value in range(1, 5): |
使用list()构造函数可以将range()生成的结果直接转换为列表。
1 | # 生成range |
元组 Tuple
元组([ˈtʌpəl])是不可修改的序列类型,即不能对其中的元素进行修改。
- 使用圆括号
()表达一个空的元组,例如(); - 向只拥有一个数据项的元组最后添加逗号,例如:
(1,) - 使用逗号分隔不同的数据项,例如:
(1, 2, 3); - 使用列表理解,例如
[x for x in iterable]; - 使用内建的
tuple()或者tuple(iterable)构造函数;
1 | # 定义元组 |
元组都可以使用+和*进行运算,也可以组合或者复制,然后获得一个新的元组。
1 | (1, 2, 3, "A", "B") + (4, 5, 6, "C", "D") # 输出(1, 2, 3, 'A', 'B', 4, 5, 6, 'C', 'D') |
上面介绍的列表 List,也可以进行类似操作。
字典 Dictionary
Python
官方文档当中,将列表(List)和元组(Tuple)归纳为序列类型(Sequence
Types),而将字典(_
dict_)类型归为映射类型(Mapping
Types)。Python
中的字典类型是使用花括号{}包裹并通过逗号,分隔的key-value键值对,例如:{"name": "hank", "age": 33}。当然,同样也可以通过class dict(**kwarg)、class dict(mapping, **kwarg)、class dict(iterable, **kwarg)构造函数进行创建。
1 | # 定义字典 |
字典的key值必须是不可变的,因此可以使用数字、字符串、元组作为键值。但是由于列表的元素是可变的,因此被不能作为字典的键值。
1 | # 打印一个使用元组作为key的字典元素 |
条件判断
Python 的条件判断语句与其它类 C 语言相似,但是每个 condition
后面需要使用冒号:表示后面是满足条件后执行的语句块。需要注意的是,Python
语句块的划分是通过缩来完成的,相同缩进数量的语句构成一个语句块。
1 | if condition1: |
下面的代码是一个条件判断语句的例子,当if和elif判断的结果都为False时,最终打印else子句的结果。
1 | if False: |
Python 当中没有
switch/case语句。
循环
while 循环
Python 中使用while循环时,需要特别注意与其它类 C
语言语法的不同,即语句后的标识符:与代码块缩进。
1 | index = 1 |
注意了,Python 是没有
do/while循环的。
可以通过设置条件表达为True实现无限循环,请看下面的例子:
1 | while True: |
如果while循环体当中只拥有一条语句,可以将其与while关键字书写在同一行,因此上面无限循环的示例也可以写成下面这样:
1 | while True: print("Thit is an infinite loop") |
Python 的while循环拥有一个与其它类 C
语言截然不同的用法,即使用while/else语句在条件判断为False时执行else语句块当中的内容。
1 | index = 1 |
for 循环
Python
的for语句可以用来对列表、元组、字典、字符串进行遍历操作。
1 | cars = ['FORD', 'HONDA', 'BMW'] |
for语句同样可以结合else一起使用,for循环完毕之后,就会执行else子句中的代码。
1 | string = "成都" |
break 与 continue
在 Python
的循环语句当中,可以通过break强行跳出当前循环体。
1 | for number in [0, 1, 2, 3, 4, 5]: |
也可以通过continue直接略过本次循环。
1 | for number in [0, 1, 2, 3, 4, 5]: |
pass
pass被执行的时候,并不进行任何操作,只起到一个语法占位符的作用。
1 | def demo(arg): pass # 定义一个不进行任何操作的函数 |
可以通过定义一个只有pass语句的类,来实现类似 C
语言结构体的功能。
1 | class Engineer: |
函数
Python
使用关键字def来定义函数,使用方式和声明规则与其它类 C
语言相似。
1 | # 定义函数 |
同其它类 C 语言一样,Python 中的变量也可以分为局部变量(定义在函数内部)和全局变量(定义在函数外部)。
1 | # 定义函数 |
命名参数
调用 Python 函数时,可以向其传递命名参数,指定该参数值由哪个函数参数进行接收,避免按照顺序接收所可能带来的潜在错误。
1 | def function(parameter): |
默认参数
定义 Python 函数的时候,对于缺省的参数可以赋予其一个默认值。
1 | # 定义函数的时候声明了parameter2的默认参数 |
可变参数列表
定义函数时,可以使用星号*作为前缀来声明一个可变参数列表,用来接收调用函数时传递的任意个数参数,这些参数会被包装至一个元组。
1 | # 在可变参数之前,可以放置任意数量的普通参数 |
也可以使用**作为前缀来声明参数,此时这些参数会包装为一个字典。
1 | def demo(parameter, **dictionary): |
如果*号单独出现在函数参数当中,那么后续的参数则必须使用命名参数显式传入。
1 | def demo(parameter1, *, parameter2, parameter3): |
lambda 函数
Python 的 lambda 函数是只由一个 Python 表达式所组成的匿名的内联函数,其语法书写形式如下:
1 | lambda [parameters]: expression |
lamdba 函数的语法只能包含一条语句,例如:
1 | demo = lambda parameterA, parameterB: print(parameterA / parameterB) |
return 语句
return语句用于退出函数并返回函数的执行结果值,具体用法如下代码所示:
1 | def demo(parameter1, parameter2): |
当 Python
中的return语句没有返回值时,则默认返回值为None。
1 | def demo(): |
不带参数值的
return语句返回None。
作用域
Python
当中仅module模块、class类、def或lambda函数会引入新作用域,if/elif/else、try/except、for/while等代码块并不会引入新作用域,即这些语句当中定义的变量在其外部也能访问。
1 | def function(): |
global关键字
使用global关键字声明的标识符将会引用至全局变量,在局部作用域中对其进行的修改操作都将会保留下来,就如同操作真正的全局变量一样。
1 | text = "全局变量" |
nonlocal关键字
使用nonlocal关键字声明的标识符将会引用至当前作用域外层的变量,在当前作用域对其进行的修改操作都将会保留,如同在真正的操作该作用域外层的变量一样。
1 | def outer(): |
类与实例
Python
使用class关键字创建一个类,然后直接调用类名即其初始化方法就可以创建这个类的实例。类进行实例化时,会自动调用该类的初始化方法__init__(self)(作用类似于
Java 当中的构造函数)。
1 | # Dog类 |
注意:类方法(包括初始化方法)中的
self参数是不能省略的,该参数指向类的实例,而非类本身。当然,根据个人编码习惯,也可以将self置换为其它语言中更为常用的this进行命名。
继承
Python 做为面向对象的语言,自然是支持继承的。需要继承一个类,只需要在定义子类时传入父类的名称即可,同时为了保证子类和父类都能够正确的实例化,子类的初始化方法需要显示调用父类的初始化方法。
1 | # 定义Dog父类 |
如同 Java 一样,Python
也是可以实现多重继承的。多重继承时,为了保证继承树能够正确的进行实例化,需要在子类的初始化方法__init__内显式的调用父类们的初始化方法,并将子类的self属性传递过去。
1 | class A: |
私有属性和方法
在类中声明属性和方法时添加两条下划线__,就可以将这个属性和方法声明为私有的。私有属性和方法只能在类中通过self.__private进行访问,而不能在类实例化后进行访问。
1 | class demo: |
方法重写 override
如果父类中定义的方法不能满足要求,那么可以考虑在子类中对父类的方法进行重写。
1 | class Parent: |
当然,也可以通过super()函数显式调用被子类重写了的父类方法。对于上面的例子,可以使用如下语句调用父类的method()方法。
1 | super(Child, childInstance).method() # 输出:Parent |
迭代器
大家可能注意到许多容器对象能够使用for语句进行循环处理,就像下面代码这样:
1 | for element in [1, 2, 3]: |
这样的处理方法简单明了,实质上for语句调用容器对象上的iter()方法,该方法返回一个迭代器对象,这个迭代器对象当中定义了一个__next__()方法用于操作容器对象的元素,当没有更多可供迭代的元素时,该方法将会抛出一个StopIteration异常通知for语句终止循环操作。这里你可以通过next()内置函数去调用__next__()方法,参见下面的例子:
1 | string = 'abc' |
定义一个iter()方法,该方法用next()方法返回一个对象。如果该类定义了next(),那么iter()就可以返回self。
1 | # 迭代器,用于反向循环一个序列 |
生成器
生成器 Generator 是一个用于建立迭代器 iterators
的简单又强大的工具,其书写方式类似于函数,但是在返回数据的时候使用了yield语句。当生成器的next()每次被调用的时候,生成器会恢复到其离开的位置(生成器能够记忆所有的数据和最后执行的语句位置)。
1 | def reverse(data): |
上述代码实现了之前迭代器示例相同的功能,生成器函数代码如此短小精悍的原因在于iter()和next()方法的创建以及StopIteration异常抛出都是自动进行的。另外生成器函数的局部变量和执行状态在每次调用都会被保存,这样比前面基于
class
的迭代器总是手动处理self.index和self.data更加便捷。
一些简单的生成器可以使用特殊语法书(与列表解析相似,不过使用圆括号代替了)书写为一种更加简捷的表达式,即生成器表达式。这种表达式常用于在闭包函数内使用生成器的情况,语法上比完整的生成器定义更紧凑,并且比同等的列表理解更加容易记忆。
1 | # 求平方和 |
异常处理
与其它类 C 语言一样,Python
通过try...except语句块提供了健全的错误和异常处理机制。首先,try和except当中的子句被执行,此时如果没有异常出现,except子句会被跳过,同时try语句块正常执行完成。如果try的子句当中发生了异常,则会中断剩下子句的执行流程,并跳转去执行except关键字后声明异常类型所对应的语句,完成后继续执行该try语句块后续的内容。如果对应的异常类型没有找到,该异常会被传递到try语句块之外,如果语句块外依然没有进行相应的处理,那么程序的执行流程会被中断
,并且向控制台打印出异常信息。
1 | try: |
当然,也可以在一个except子句中捕捉多个异常。
1 | except (RuntimeError, TypeError, NameError): |
如果except子句中的异常类具有继承关系,则它们都将会被触发。
1 | # 继承Exception类 |
如果将上面代码中
except子句的处理顺序颠倒一下,那么打印结果会变为ExceptionA ExceptionB ExceptionC,这是因为异常类 A、B、C 产生的异常全部都会被异常类 A 捕捉然后中断执行。
值得注意的是,最后一条except子句可以省略掉异常名称,从而可以补捉到全部的异常类型,虽然同样可以执行打印错误信息和抛出异常的操作,不过要十分小心的使用,因为它可能会掩盖掉真实发生的异常信息。
1 | try: |
try…except…异常处理语句还拥有一个else…子句,用来在try子句没有捕捉到异常时执行一些必要的代码(如果try…except…时发生了异常,则else…子句中的异常将不会得到执行)。
1 | try: |
可以在raise子句当中声明异常的参数,并在except当中通过as关键字进行实例化以后进行接收。
1 | try: |
由于
Exception类里定义了__str__()方法,所以可以通过直接打印异常对象来获取异常参数。
Python
的异常处理机制,不光能处理try子句当中发生的异常,还能够处理try中调用的函数内发生的异常。
1 | def division(): |
raise子句当中所要抛出的异常类必须继承自Exception,当异常被触发的时候,该异常类会被自动实例化并将执行流程带入except子句。
1 | class MyError(Exception): |
如果希望不对抛出的异常进行处理,那么可以选择在except子句内重新将这个异常抛出。
1 | try: |
开发人员可以自定义异常类,这些自定义的异常类必须继承自内置的Exception类。自定义异常类通常只会定义几个用来描述异常的属性,从而保持类定义的简单明了。对于一个模块发生多个错误,可以通过建立一个异常类的继承树来进行体现,来看下面的例子:
1 | # 针对该模块的自定义异常基类 |
Python 异常的命名通常会以
"Error"结尾,建议自定义异常时保持这样的惯例。
try语句还拥有一个可以用来进行一些清除操作的finally子句,该子句无论不否发生异常都会被执行(与
else 的最大不同点),读者可以参考下面的例子:
1 | def divide(x, y): |
模块管理
Python
通过import关键字来引入其它模块,并且需要将其放置到代码的顶部。Python
当中.py文件的名称就是模块的名称,模块的名称可以通过全局变量__name__进行访问(如果该模块是
python
命令行直接执行的模块,则__name__属性的打印结果为"__main__")。
1 | # myModule.py |
1 | # main.py |
1 | # 打印结果 |
每个模块都拥有自己的私有符号表(Symbol
Table,一种存储键值对的数据结构),因为被引入的模块名称会被放置在引入模块的全局全局符号表当中,所以模块当中定义的函数能够以全局符号表的方式进行使用。因此,模块的作者可以放心的在模块中使用全局变量,而毋须担心与其它用户的变量发生冲突。另一方面,如要需要访问这些模块里定义的全局变量
,那么可以通过module_name.variable_name的方式进行访问。
如果觉得module_name.variable_name方式过于繁琐,那么可以通过from module_name import iitem_name_in_module语句指定从模块导入的内容,而无须总是在使用的时候添加模块的名称,请见下面的例子:
1 | # module.py |
1 | # main.py |
当然,如果觉得比较麻烦,还可以使用from module import *一次性导入module模块当中的内容。但是需要注意的是这样并不能导入模块中以下划线_作为前缀的内容,比如下面这样:
1 | # module.py |
1 | from module import * |
这种一忺导入全部模块内容的方式在 Python 官方文档中是不被鼓励的,因此在现实开发场景下需要酌情使用。
如果引入模块的名称与当前模块定义的变量或者函数有冲突,那么可以考虑通过as关键字使模块中的内容绑定到一个别名上。
1 | # module.py |
1 | # main.py |
当然,也可以将from...import...as...结合起来使用,这样做会让代码更加简化。
1 | # main.py |
出于性能方面的考量,一个模块只会在 Python
的每个解释器会话当中被引入一次,所以如果开发人员在解释器运行之后修改了模块的代码,则必须重新启动解释器。当然,如果你只有一个模块需要进行交互式的测试,则可以使用importlib.reload()方法暂时解决这个问题。
1 | import module |
以脚本方式执行模块
当在控制台直接执行 Python
脚本文件的时候,模块的__name__属性值会被设置为"__main__",可以利用这个特性在模块文件在命令行以python module.py直接进行执行的时候,进行一些特定的交互和操作。
1 | # module.py |
1 | ➜ git:(master) ✗ python3 main.py 2018 |
模块的搜索的路径
当一个模块名字被引入时,Python
解释器会首先搜索内置模块是否存在该名称,如果不存在,则会按照sys.path属性的顺序进行搜索。即首先是当前.py脚本所在的目录,然后是
Python 环境变量相关的目录,最后进行 Python 安装相关的目录。
1 | import sys |
预编译
为了加快模块的加载速度,Pytho
缓存了__pycache__目录下每个模块的编译版本至module.version.pyc名称下,例如CPython
release
3.6里的main.py模块将会被缓存为__pycache__/main.cpython-36.pyc,这样的命名约定可以使不同
Python 版本的编译模块能够同时共存。
Python 根据编译版本检查源代码的修改日期,以确定它是否过期,是否需要重新编译。这是一个完全自动的过程。此外,编译后的模块是独立于平台的,因此相同的库可以在具有不同体系结构的系统之间共享。
Python 在两种情况下不检查缓存。首先,它总是重新编译,不存储直接从命令行加载的模块的结果。其次,如果没有源模块,它不会检查缓存。要支持非源(仅编译)发行版,编译后的模块必须位于源目录中,并且不允许有源模块。
Python 在两种情况下不会检查缓存。首先,从命令行直接加载的模块总是会重新进行编译;其次,如果当前没有源模块时就不会检查缓存。为了支持非源(仅编译可用)的发行版,被编译的模块必须位于源目录,并且它们必须不能是一个源模块。
需要提醒一些资深的使用者:
- 你可以使用
-O或-OO控制 Python 命令编译模块的尺寸,参数-O会移除 assert 语句,-OO会移除 assert 语句和__doc__字符串。由于有些程序可能依赖于这些选项,所以只有在知道自己在做什么时才应该使用这此选项。经过优化的模块会拥有一个opt-标识并且通常情况下尺寸会更小。但是未来的 Python 版本可能会调整这些优化的效果。 - 从
.pyc文件读取的程序并不会比从.py文件读取的运行速度更快,.pyc文件唯一提高的是加载速度。 - 模块
compileall能够为一个目录下的所有模块建立.pyc文件。
Python 内置的标准模块,有些是依赖于操作系统底层实现的,例如
winreg模块只供在 Windows 系统上使用。但是模块sys比较特殊,它可以用于几乎所有平台的 Python 解释器。
dir()方法
Python
内置的dir()方法能够以字符串格式输出模块当中所定义的内容。
1 | # module.py |
1 | # main.py |
1 | main.py里的属性与方法: ['__annotations__', '__builtins__', '__cached__', '__doc__', '__file__', '__loader__', '__name__', '__package__', '__spec__', 'module', 'sys'] |
可以通过向dir()方法传递内置的标准模块builtins来获取
Python 内建的函数和变量。
1 | import builtins |
1 | ['ArithmeticError', 'AssertionError', 'AttributeError', 'BaseException', 'BlockingIOError', 'BrokenPipeError', 'BufferError', 'BytesWarning', 'ChildProcessError', 'ConnectionAbortedError', 'ConnectionError', 'ConnectionRefusedError', 'ConnectionResetError', 'DeprecationWarning', 'EOFError', 'Ellipsis', 'EnvironmentError', 'Exception', 'False', 'FileExistsError', 'FileNotFoundError', 'FloatingPointError', 'FutureWarning', 'GeneratorExit', 'IOError', 'ImportError', 'ImportWarning', 'IndentationError', 'IndexError', 'InterruptedError', 'IsADirectoryError', 'KeyError', 'KeyboardInterrupt', 'LookupError', 'MemoryError', 'ModuleNotFoundError', 'NameError', 'None', 'NotADirectoryError', 'NotImplemented', 'NotImplementedError', 'OSError', 'OverflowError', 'PendingDeprecationWarning', 'PermissionError', 'ProcessLookupError', 'RecursionError', 'ReferenceError', 'ResourceWarning', 'RuntimeError', 'RuntimeWarning', 'StopAsyncIteration', 'StopIteration', 'SyntaxError', 'SyntaxWarning', 'SystemError', 'SystemExit', 'TabError', 'TimeoutError', 'True', 'TypeError', 'UnboundLocalError', 'UnicodeDecodeError', 'UnicodeEncodeError', 'UnicodeError', 'UnicodeTranslateError', 'UnicodeWarning', 'UserWarning', 'ValueError', 'Warning', 'ZeroDivisionError', '__build_class__', '__debug__', '__doc__', '__import__', '__loader__', '__name__', '__package__', '__spec__', 'abs', 'all', 'any', 'ascii', 'bin', 'bool', 'bytearray', 'bytes', 'callable', 'chr', 'classmethod', 'compile', 'complex', 'copyright', 'credits', 'delattr', 'dict', 'dir', 'divmod', 'enumerate', 'eval', 'exec', 'exit', 'filter', 'float', 'format', 'frozenset', 'getattr', 'globals', 'hasattr', 'hash', 'help', 'hex', 'id', 'input', 'int', 'isinstance', 'issubclass', 'iter', 'len', 'license', 'list', 'locals', 'map', 'max', 'memoryview', 'min', 'next', 'object', 'oct', 'open', 'ord', 'pow', 'print', 'property', 'quit', 'range', 'repr', 'reversed', 'round', 'set', 'setattr', 'slice', 'sorted', 'staticmethod', 'str', 'sum', 'super', 'tuple', 'type', 'vars', 'zip'] |
包
Python
将多个模块的集合称为包,包通过带点的模块名来构建 Python
的命名空间,例如模块名A.B表示在A包下建立的B子模块。
1 | # ./directory/module.py |
1 | # main.py |
1 | # main.py |
注意,当使用from package import item格式语法的时候,item可以是一个子模块、子包、或者是定义在包中的函数、类、变量。这种情况下import语句首先会测试item是否定义在包中,如果没有则会被认为是一个模块,并且尝试去加载它。如果加载出现问题,则会抛出一个ImportError异常。
相反,使用import item.subitem.subsubitem格式语句的时候,除最后一个item以外每个item都必须是包,最后一个项目可以是模块或者包,但不能是前一个item中定义的类、函数、变量。
from ... import *
如果需要引入一个包下的所有子模块,必须显式的提供一个包的索引。如果一个包的__init__.py代码里定义了一个名为__all__的列表,它将被视为将要被from package import *引入的模块名称的列表。例如,对于一个package目录内的__init__.py文件可能包含如下内容:
1 | __all__ = ["echo", "surround", "reverse"] |
上面意味着from package import *将会引入package目录下的echo、surround、reverse3
个子模块。如果这里的__all__属性没有被定义,则from package import *语句就不会将子模块引入当前的命名空间,它只会确保package包被引入,并且也会执行__init__.py中的其它代码,然后引入包内定义的各种名称(包括由__init__.py以及子模块定义的)。
通过相对路径引用包
Python
当中,from...import...同样可以通过相对路径访问包。
1 | from . import package |
注意:相对路径的
import是基于当前模块名称的,由于主模块名称总是"__main__",所以用于作为 Python 应用程序的主模块必须始终使用绝对导入。
处理多个目录中的包
Python
中的包支持一个特殊的属性__path__,它可以被初始化成一个包含目录名称的列表,这个列表可以在该代码文件执行之前处理包的__init__.py。这个变量可以修改的,这样做会影响将来对包中包含的模块和子包的搜索。
虽然通常不需要这个特性,但是可以通过它来扩展包中的模块集合。
虚拟环境
虚拟环境(Virtual
Environment)是一个自包含的目录树,用来管理 Python 第 3
方包依赖。不同的 Python
项目可以使用不同的虚拟环境,例如:应用程序A可以安装自己的1.0版本的虚拟环境,而应用程序B具有另一个2.0版本的虚拟环境,如果应用程序B需要将依赖库升级至3.0版本,这并不会影响应用程序B的虚拟环境。
Python 官方提供了一个虚拟环境的轻量级实现模块venv,较新版本的 Python 发行包里已经默认内置了其实现,可以直接进行使用。
1 | python3 -m venv my-project |
上面的语句执行之后,将会建立一个my-project目录,里面包含一个
Python 解释器的拷贝,以及相关的第 3 方依赖库,在 Python3.6.6
下执行得到的目录结构如下:
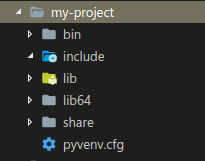
当建立完成项目的虚拟环境之后,可以通过如下命令进行激活:
1 | # On Windows |
激活后将会改变当前 Shell 的显示信息,以提示开发人员当前正在使用的是哪个虚拟环境。
1 | ➜ /workspace source my-project/bin/activate |
virtualenv是一个第 3 方社区提供的独立 Python 虚拟环境,同时支持 Python2 和 Python3 版本。在 Python3.3 以后,官方提供了上述的
venv模块原生支持虚拟环境,因此virtualenv逐步废弃使用。
包管理
Python
可以使用应用程序pip安装、升级、移除第三方依赖包,正常情况下pip已经伴随
Python 解释器默认安装,如果当前 Python 默认安装的 pip
版本过低,那么可以通过pip install -U pip或python -m pip install --upgrade pip命令手动进行安装。
1 | # 搜索包 |
pip freeze将会生成已安装的包列表,但输出格式使用了pip install所期望的格式,通常
Python 约定将该列表放置到一个requirements.txt文件。
1 | (my-project) ➜ pip freeze > requirements.txt |
然后可以将requirements.txt文件伴随应用程序一起提交至版本管理系统当中,然后其它用户可以在同步代码之后使用pip install -r requirements.txt安装所需的包。
1 | (my-project) ➜ pip install -r requirements.txt |
输入输出
Python 内置了许多方法去完成输入输出操作,这些方法能够将数据以人类可读的形式打印出来,也可以将其写入文件当中供将来使用。
输出格式化
Python
提供了两种字符串格式化输出的方法,一种是使用format()函数进行格式化输出,另一种是通过print()函数的格式化占位符完成。
1 | print("{}是中国的一个{}".format("成都", "省")) |
1 | print("%s是中国的一个%s" % ("成都","省")) |
Python
当中可以使用str()和repr()方法将任意值转换成为字符串。其中str()会返回人类可读的字符串,repr()则会生成
Python 解释器能够读取的格式。
1 | string = str("Hank\n"); |
文件读写
Python
当中open(filename, mode, encoding)函数会返回一个file对象,其中filename是需要打开的文件名,mode用于标识以何种方式打开文件,encoding指定读写操作的编码格式。
| 模式 | 意义 |
|---|---|
"r" |
以读方式打开(默认)。 |
"w" |
以写方式打开,并清除之前内容。 |
"x" |
创建文件,如果文件已经存在则操作失败。 |
"a" |
以写方式打开,并在之前内容的尾部追加新内容。 |
"b" |
二进制模式。 |
"t" |
文本模式(默认)。 |
"+" |
打开一个磁盘文件进行读写操作。 |
"U" |
通用换行模式(已废弃)。 |
使用file对象的最佳实践是与with关键字结合在一起,从而保证file对象总是能在恰当的时间关闭,即使出现异常,使用with关键字也比书写等效的try-finally简洁,这个在接下来的对象清理章节有更详细的讲解。
1 | with open("demo.txt", mode = "r", encoding="utf8") as file: |
如果file对象已经被with关键字或者close()方法关闭,后续任何对file对象的操作都将会失败,比如下面的例子:
1 | file.close() |
使用readline()方法可以每次只读取一行数据。
1 | with open("demo.txt", mode = "r", encoding="utf8") as file: |
当然,也可以通过循环file对象来读取目标文件中的每行数据。
1 | with open("demo.txt", mode = "r", encoding="utf8") as file: |
如果需要读取指定文件的全部内容,还可以采用
list(file)或file.readlines()方法。
write(string)用于写入字符串内容到文件,并返回写入的字符数量。
1 | with open("demo.txt", mode = "w", encoding="utf8") as file: |
对象清理
Python 当中的一些预定义对象会内置清理行为,可以在对象不再需要的时候被自动执行。
1 | for line in open("myfile.txt"): |
上面这段代码的问题在于,代码执行完后没有立即关闭打开的文件。这在相对简单的脚本代码中不算问题,但对于更大规模的应用而言就是严重的错误。因此,Python
提供了with语句来确保file这样的对象在使用后能够被正确的清理和关闭。
1 | with open("myfile.txt") as file: |
上面语句执行之后,即使读取文件数据时出现问题,file对象也能正常关闭,因为file对象已经预定义了相关清除行为。
Python 之禅
可以在 Python 命令行模式输入import this得到一份关于
Python 的优秀指导原则《Python 之禅》。
- 优美胜于丑陋。
- 明了胜于晦涩。
- 简洁胜于复杂。
- 复杂胜于凌乱。
- 扁平胜于嵌套。
- 间隔胜于紧凑。
- 保持良好可读性。
- 即便是特例也不可打压破这些规则。
- 实用性胜过纯粹性。
- 对错误与异常不能保持沉默,除非你刻意需要这样做。
- 面对模棱两可拒绝猜测,应该寻找最好的一个解决方案。
- 虽然动手做好过于什么都不做,但是仔细思考以后再动手胜过于盲目的去做。
- 如果实现难以解释,这必然是一个坏主意。
- 如果实现易于解释,这可能是一个好主意。
- 命名空间是非常好的主意,要善于进行利用。
通过 JSON 保存数据
JSON 可以用来保存诸如嵌套的字典或者列表这样的结构化数据,Python
提供了json模块来处理 JSON
格式数据,具体使用方法请参见下面的示例代码:
1 | import json |
也可以在打开文件之后,将文件内容序列化为 JSON 格式。
1 | import json |
通过 XML 方式合成 SVG
SVG 本质是基于 XML 语言进行描述的矢量图形,由于 Python
内置的ElementTree组件类提供了丰富的操作 XML
树形结构的方法;因此在下面这份简单的示例代码当中,将基于ElementTree来完成
SVG 图片文件的合并工作。
1 | import xml.etree.ElementTree as ET |
言简意赅 の Python3